Hi!
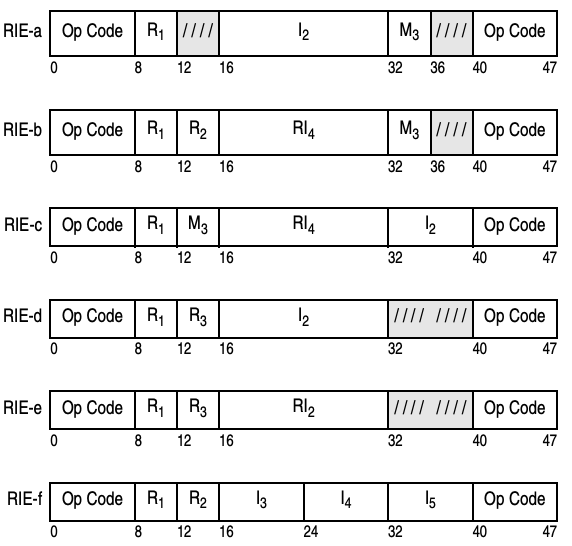
WillTrojak January 29 I’ve been doing some work on a domain-specific compiler for Power, and a minor issue has been that there are multiple subtypes for each instruction format. For example, in 3. 1c there are 4 A-form formats. I wondered if
I’ve been doing some work on a domain-specific compiler for Power, and a minor issue has been that there are multiple subtypes for each instruction format.
For example, in 3.1c there are 4 A-form formats.
Five.
I wondered if people would be open to a more concrete name scheme for these sub-forms? This would mean forms are unambiguous but also immutable in future ISAs, with new sub-forms just appended.
In most cases it is just the labels of the fields that change. They aren’t really different forms. One exception (maybe the only one?) is M-form, where the variant with RB is very different from the one with the immediate SH field.
If your assembler has problems with the names of the instruction forms, just don’t use them at all?
Segher
Unless otherwise stated above:
IBM Nederland B.V.
Gevestigd te Amsterdam
Inschrijving Handelsregister Amsterdam Nr. 33054214